단절점과 단절선
이 글을 보기 전에, DFS Spanning Tree를 읽고 오는 것을 권장한다. DFS Spanning Tree를 통해 일반 그래프를 트리로 표현하는 방법에 대해 공부했다. 이제 간선 분류를 통해 그래프에서 의미 있는 정점, 간선들을 찾는 방법에 다룰 것이다. 그 중 대표적인 예시가 바로 Articulation Point와 Bridge이다. 이들은 무향 그래프에서만 정의되는 개념이므로, 연결 관계에 관련된 개념이다. 하나의 컴포넌트로 구성되어 있는 그래프에서, Articulation Point와 Bridge는 다음과 같이 정의한다.
특정 정점을 제거하였을 때, 컴포넌트 수가 증가하면 그 정점은 Articulation Point이며,
특정 간선을 제거하면 컴포넌트 수가 증가하는 간선을 Bridge라 한다.
즉, 제거했을 때 그래프가 둘 이상으로 나누어지는 정점/간선을 각각 단절점/단절선이라고 한다.
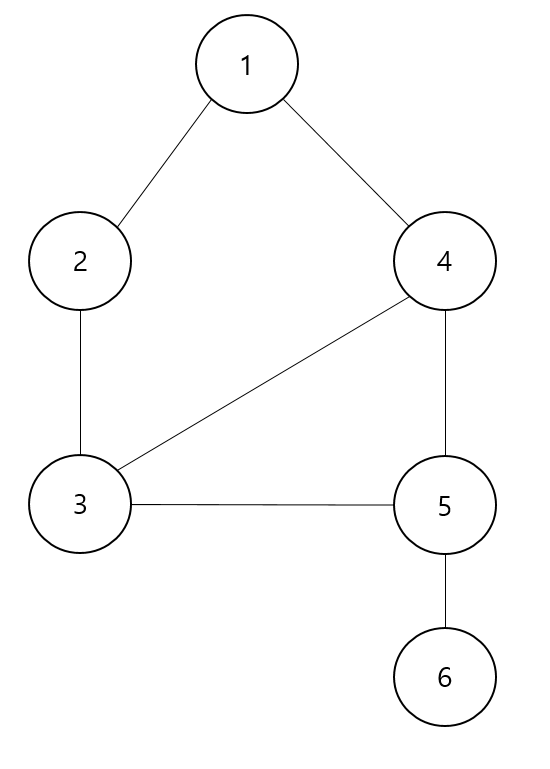
위 그래프에서는 $5$번 정점을 제거하면 그래프가 {1, 2, 3, 4}와 {6}의 두 컴포넌트로 분리되므로 $5$만이 단절점이다.
또한 정점 $1$, $2$, $3$, $4$번 정점은 사이클을 이루므로 이들 중 어느 두 정점 간의 간선도 단절선이 아닐 것이다. 하지만 정점 $5$, $6$을 잇는 간선을 제거하면 정점 $6$이 그래프와 분리되어 다른 컴포넌트가 되기 때문에 단절선이라고 볼 수 있다.
그렇다면 구하는 방법을 생각해보면, 임의의 정점/간선에 대해 그를 제거하고 DFS를 시행하여 컴포넌트의 개수를 세어주는 가장 단순한 방법을 생각해볼 수 있다. 이 때 시간복잡도는, 각각의 정점/간선에 대해 DFS를 한 번씩 시행하므로 어림잡아 $O(V^2)$이 소모될 것이다.
Naive Solution : 임의의 정점 / 간선을 삭제한 후, DFS를 통해 컴포넌트의 수를 세는 $O(V^2)$의 방법
본 글의 목표는 DFS Spanning Tree를 통해 이를 $O(V)$에 구하는 것을 목적으로 한다.
How to Work
DFS 스패닝 트리가 구성된 상황을 생각해보자. 무향 그래프이므로 간선의 종류는 Tree Edge, Backward Edge가 유일하다. 다르게 말하면 $V$개의 정점과 $V-1$개의 간선으로 구성된 Tree에, 몇 개의 간선이 추가(Backward Edge)된 형태라고 볼 수 있다. 이러한 이해를 바탕으로, 아래의 값을 고민할 것이다.
low[x] : x번 정점 or x번의 자손 정점에서 Backward Edge를 통해 올라갈 수 있는 가장 높은 정점
'올라간다'라는 것은 루트를 향한다는 것이고, 가장 높다는 것은 루트와 가까울수록 높음을 의미하는 것이다. 예시를 통해 low 값을 이해해보면
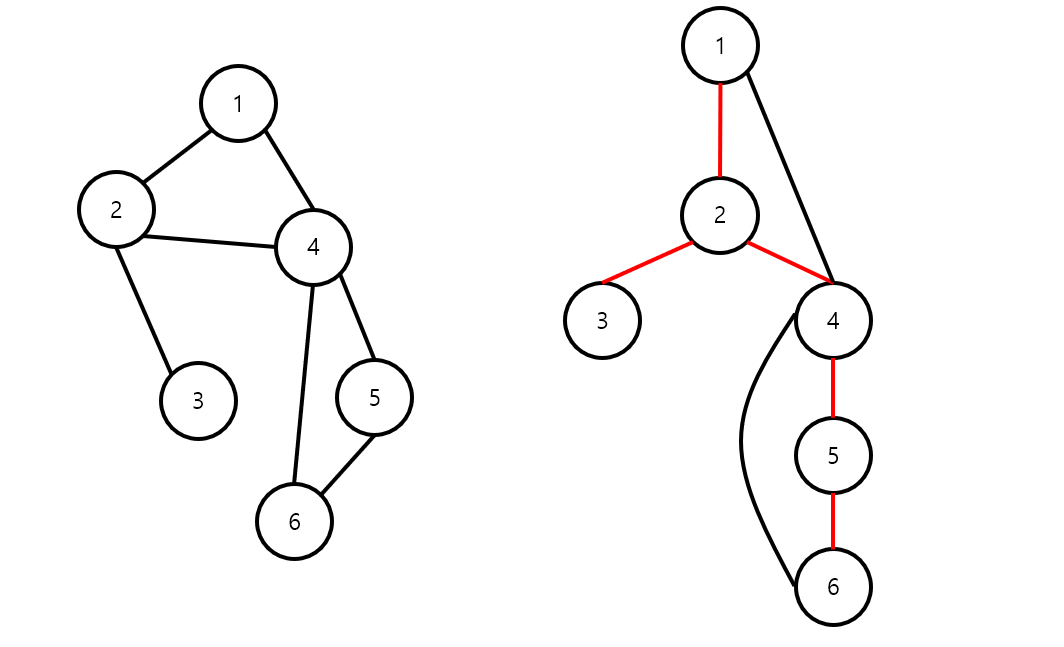
왼쪽 그래프에서 Tree Edge를 빨간색으로 표시하여 오른쪽에 나타내었다. 각각의 정점에 대해 low 값을 구해보면
low[1]은 1번 정점이 루트 노드이므로 1번이다.
low[2]는 '2번 정점 or 2번의 자손인 3~6번' 중 4번에서 Backward Edge를 통해 1로 올라갈 수 있으므로, 1번이다.
low[3]은 '3번 정점'에서 Backward Edge로 올라갈 수 있는 정점이 없으므로 3번 자기 자신이다.
low[4]는 '4번 정점 or 4번의 자손인 5, 6번'에서 Backward Edge를 통해 올라갈 수 있는 가장 높은, 4번이다.
low[5]는 '5번 정점 or 5번의 자손인 6번'에서 Backward Edge를 통해 올라갈 수 있는 가장 높은 4번이다.
low[6]은 '6번 정점'에서 Backward Edge를 통해 올라갈 수 있는 4번이 가장 높은 정점이다.
이처럼 모든 정점에 대해 low 값을 계산할 수 있고, 이를 바탕으로 단절점 / 단절선 여부를 판단한다.
DFS Spanning Tree에 대해 추가적으로 설명하자면, 무향 그래프에서는 간선이 Tree Edge, Backward Edge 밖에 존재하지 않는다. 특히 Cross Edge는 존재할 수 없다.( 증명은 DFS Spanning Tree 글을 참고하라. ) 즉, 만약 위 그래프에서 (3, 6)이라는 Edge가 존재했다면, 이는 Cross Edge가 될 수 없었으므로 DFS 과정에서 Tree Edge가 될 것이라고 생각할 수 있다.
즉, Cross Edge가 존재하지 않는 것은, Backward Edge가 '같은 분기(Branch)에 있는 정점을 연결하는 간선'임을 설명한다.
예를 들어 간선 (1, 4)는 분기 {1, 2, 4}의 두 정점을 연결하며, 간선 (4, 6)은 분기 {4, 5, 6}의 두 정점을 연결한다. 이러한 관점에서, 무향 그래프의 Backward Edge는 다른 분기 간의 연결에는 관여하지 않는 형태임을 이해할 수 있다.
이제 low 값을 어떻게 활용하는지에 대해 설명할 것이다. 먼저 DFS ordering을 통해 각 정점에 번호를 재부여한다. 이를 정점 x에 대해 num[x]라고 하고, low 값으로 사용하는 정점 번호 또한 재부여된 번호를 의미함에 유의하라.
( 간단하게 설명하자면, DFS를 통해 정점의 번호를 방문 순서로 바꾸어준 후, low 값을 구한다고 보면 된다. 이 떄, num[x]는 x의 번호를 의미한다. )
이를 통해 같은 분기 내에 존재하는 정점 $x, y$에 대해 num[$x$] < num[$y$]는 곧, $x$가 더 위쪽에 존재함을 의미한다는 것을 알 수 있다.
low 값의 정의와, 위에서 언급한 Backward Edge의 성절을 생각해보면 다음 조건식에 의해 Articulation Point가 결정됨을 알 수 있다.
$x$의 자손 정점 $y_{i}$에 대해 num[$x$] $<=$ low[$y_{i}$]가 임의의 $i$에 대해 항상 성립한다면, $x$는 articulation point이다.
x의 자손들의 low 값이 x의 번호보다 크다는 것은, x의 자손들에서 시작해서 Backward Edge를 타고 올라가도 x보다 높이 올라가지 못한다는 것이다. 즉, x를 거치지 않는다면 x의 서브트리는 원래 그래프와 분리된다는 말이다.

위 그래프에서 4는 articulation point이다. 왜냐하면 low[5] = 4로, 5번 혹은 5번의 자손 정점에서 Backward Edge를 타고 올라가더라도 가장 높이 올라갈 수 있는 한계는 4번이기 때문이다. 즉, 4번을 자른다면, {5, 6}은 원래 그래프에서 분리된다.
반면 2번은 articulation point가 아니다. 왜냐하면 2번의 자손 중 4번 정점의 low[4] = 1이므로, 2번을 제거하더라도 2번의 자손인 4번에서, 2번을 잘랐을 때 분리되어야 할 1번과 여전히 연결되어 있기 때문이다.
이제 low 값을 어떻게 구하는지 확인할 것이다. 현재 정점을 $x$라 하고, 이와 인접한 정점 $y$에 대해 다음을 고려하자.
i) (x, y)가 Tree Edge인 경우
- 이 경우에는 low[x]를 low[y]와 비교하여 low[x]를 min(low[x], low[y])로 갱신한다.
ii) (x, y)가 Backward Edge인 경우
- low 값의 정의를 생각해보면 '역뱡향 간선만을 타고 올라갈 수 있는 가장 높은 정점 번호'이다.
- 따라서 low[x]를 num[y]와 비교하여 low[x]를 min(low[x], num[y])로 갱신한다.
Implementation
이제 위 내용을 구현하여 시간복잡도 $O(N)$에 단절점을 구할 수 있다. 코드는 다음과 같다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
vector<int> adj[MAX_V]; // 인접 리스트
int num[MAX_V]; // 방문하는 정점에 번호 부여
int cnt;
int par[MAX_V];
int low[MAX_V];
// low[x] : x 혹은 x의 자손에서 Backward Edge를 타고 올라갈 수 있는 가장 높은 정점의 num 값
// 다른 말로는 Backward Edge를 타고 올라가 얻을 수 있는 최소의 num 값
void dfs(int x)
{
num[x] = ++cnt;
// low의 초깃값
low[x] = num[x];
for(int nxt : adj[x]){
if(nxt == par[x]) continue;
// Tree Edge인 경우
if(!num[nxt]){
par[nxt] = x;
dfs(nxt);
// nxt에서 올라갈 수 있는 가장 높은 정점이 x 아래에 존재 -> x는 단절점
if(num[x] <= low[nxt]){
articulation.push_back(x);
}
low[x] = min(low[x], low[nxt]);
}
// Backward Edge인
else{
low[x] = min(low[x], num[nxt]);
}
}
}
|
cs |
간선 $(x, nxt)$를 확인하며, 간선이 Tree Edge, Backward Edge인지에 따라 경우를 나누어 판단한다. 만약 Tree Edge라면 dfs를 시행하고, x를 제거했을 때, nxt와 그의 자손들이 x보다 높이 올라갈 수 없다면 x는 단절점으로 판단된다. 또한 Backward Edge라면 low를 업데이트하고 끝난다.
단절점에 대한 구현도 이와 거의 같다. 다만 차이점은 num[x] < low[nxt]의 조건을 만족하면 (x, nxt)가 단절선이라는 것이다. 그 이유는 (x, nxt)를 잘랐을 때, 컴포넌트가 나누어지려면 nxt와 그의 자손들이 올라갈 수 있는 가장 높은 높이는 nxt 자신이어야 한다는 것이다. 즉, 이를 통해 nxt가 단절점이 된다는 성질 또한 알 수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
vector<int> adj[MAX_V]; // 인접 리스트
int num[MAX_V]; // 방문하는 정점에 번호 부여
int cnt;
int par[MAX_V];
int low[MAX_V];
// low[x] : x 혹은 x의 자손에서 Backward Edge를 타고 올라갈 수 있는 가장 높은 정점의 num 값
// 다른 말로는 Backward Edge를 타고 올라가 얻을 수 있는 최소의 num 값
void dfs(int x)
{
num[x] = ++cnt;
// low의 초깃값
low[x] = num[x];
for(int nxt : adj[x]){
if(nxt == par[x]) continue;
// Tree Edge인 경우
if(!num[nxt]){
par[nxt] = x;
dfs(nxt);
if(num[x] < low[nxt]){
Bridge.push_back({x, nxt});
}
low[x] = min(low[x], low[nxt]);
}
// Backward Edge인 경우
else{
low[x] = min(low[x], num[nxt]);
}
}
}
|
cs |
내용을 복잡하게 설명한 것 같지만, 코드는 생각보다 간결하다. 타 블로그와 달리 low의 개념을 깊이 다루고자 했는데, 이는 추후에 다룰 BCC, Cactus에서 유용하게 사용되기 때문이다.
'Algorithm' 카테고리의 다른 글
| 최단 경로 알고리즘(다익스트라, 플로이드 알고리즘) (0) | 2021.05.02 |
|---|---|
| 컨벡스 헐(Convex Hull) 알고리즘 (0) | 2021.03.27 |
| [ Query ] Sqrt Decomposition (제곱근 분할법) (2) | 2021.02.25 |
| [ Query ] 오일러 경로 테크닉 (Euler Tour Technique) (2) | 2021.02.18 |
| 벨만 포드 알고리즘(Bellman Ford Algorithm) (0) | 2021.02.14 |